Multilingual language models have many deployment challenges.
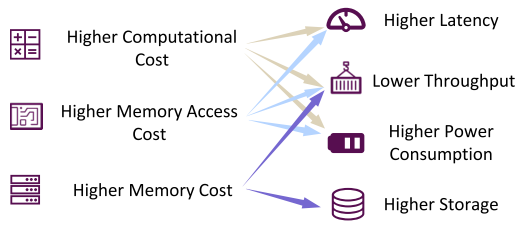
Can we engineer multilingual language models that not only match the prowess of their bulkier counterparts but do so while being more compact, quicker on their feet, and capable of handling massive data batches in real-time production environments. Is this a feat we can achieve?
.png)
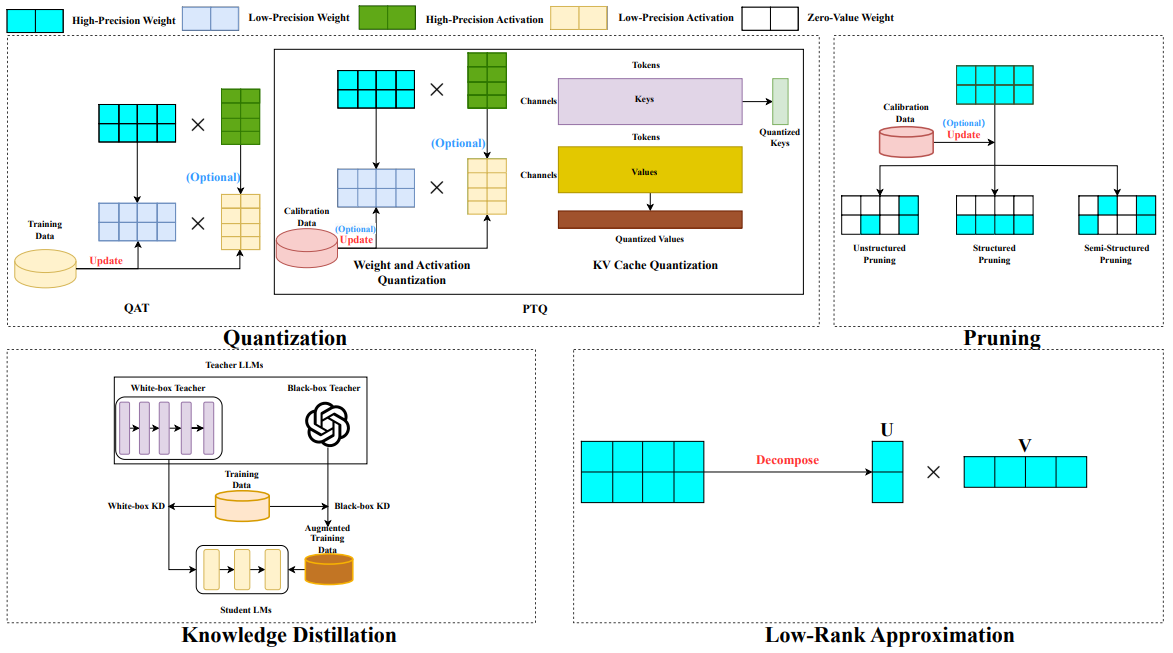
Techniques:
Pruning
Unstructured Pruning
Structured Pruning
Semi-Structured Pruning
Methods Used
- SparseGPT | GitHub
- ShortGPT | KLDBasedPruning & Perplexity Sensivities
Knowledge Distillation
- Hidden State-Based Distillation ~ DistillKit | GitHub
- Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling
- On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes
- Minitron: Compact Language models via Pruning & Knowledge Distillation
- DistiLLM: Towards Streamlined Distillation for Large Language Models
Quantization
- Quantization Aware Training (QAT)
- Post Training Quantization (PTQ)
- KV Cache Quantization
- Weight & Activation Quantization
Low-Rank Factorization
Fine-Tuning | GitHub
Datasets:
Initial 7 datasets unified, having 6.62M rows which includes the following:
- Bangla_Alpaca_Orca : Bangle
- Urdu_Instruct_News_Article_Generation: Urdu
- Urdu_Instruct_News_Headline_Generation: Urdu
- Urdu_Instruct_News_Category_Classification: Urdu
- cidar: Arabic
- Six_Millions_Instruction_Dataset_For_Arabic_Llm_Ft: Arabic
- instructv3: English
Get in touch with the team:
- Mayank Bhaskar -> mayankbhaskar007@gmail.com
- Ahmad Anis -> ahmadanis5050@gmail.com
- Drishti Sharma -> drishtisharma96505@gmail.com
- Vishnu Vardhan -> vardhanvishnu691@gmail.com
- Yaya -> yayasysco@gmail.com
- Shayekh Bin Islam -> shayekh.bin.islam@gmail.com